HashMap的内部实现
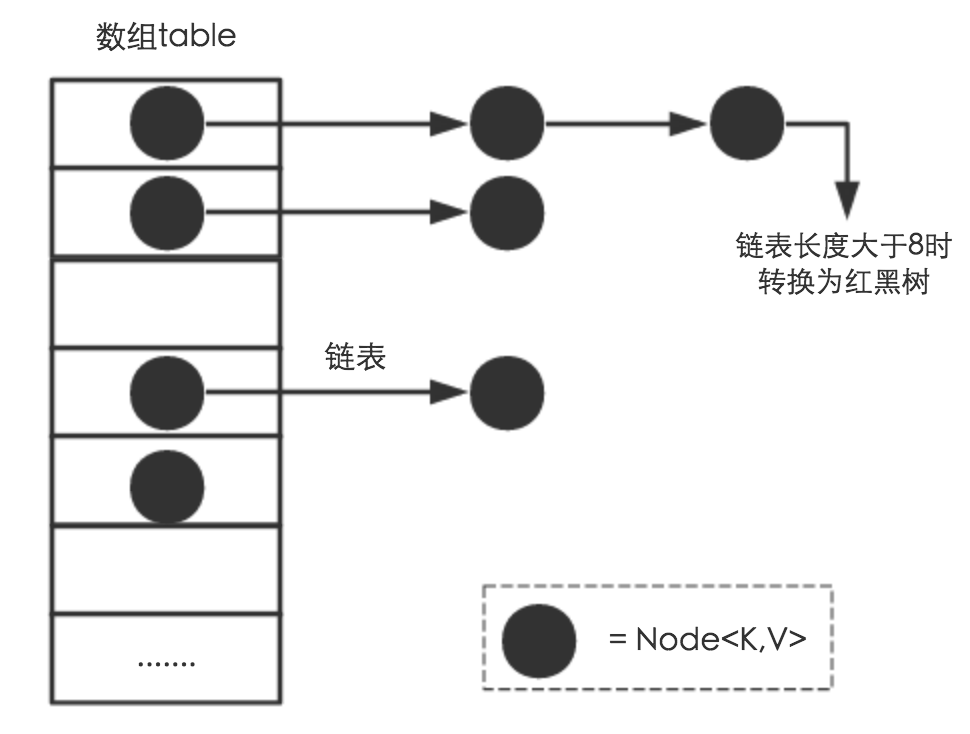
图中每一个节点为一个Entry对象,HashMap保存由一个Entry组成的数组table。
table数组的每一项Entry都维护一个链表,称为一个bucket。
private static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
final int hash;
V value;
Entry<K,V> next;
}
初始化
HashMap(int initialCapacity, float loadFactor);
- 容量(Capacity)和负载因子(Load factor)。
Capacity是Entry数组table的长度,默认为16,capacity * load factor的值为threshold,当HashMap中元素的数目大于threshold时,capacity即table的长度会扩容为当前的两倍,且对HashMap中所有元素发生再散列。
如果对迭代性能要求很高的话不要把capacity设置过大,也不要把load factor设置过小。Capacity会被设置为2的次幂,即使随便给定一个值也会被自动调整为比该值大的2的次幂。
- TREEIFY_THRESHOLD
默认为8,当一个bucket的长度大于等于TREEIFY_THRESHOLD时,该链表会被转换成红黑树。
put操作
- 对key的hashCode()做hash,然后再计算table中的下标index。
- 如果没碰撞直接放到bucket里。
- 如果碰撞了,以链表的形式存在buckets后。
- 如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD,默认为8),就把链表转换成红黑树。
- 如果节点已经存在就替换old value(保证key的唯一性)。
- 如果bucket满了(超过load factor*current capacity),就要resize。
get操作
- bucket里的第一个节点,直接命中。
- 如果有冲突,则通过key.equals(k)去查找对应的entry。
a. 若为树,则在树中通过key.equals(k)查找,O(logn)。
b. 若为链表,则在链表中通过key.equals(k)查找,O(n)。
hash函数的实现
- 对hashCode进行hash操作
//hash = h ^ (h >> 16) //高16bit不变,低16bit和高16bit做异或操作得到hash操作后的值值 static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }当进行第二步时,通过求余
hash & (n-1)得到table下标,由于数组的长度不会很大,n-1得到的值很小,如n等于15时,n-1为0x1111,只有低四位有效,因此很容易发生碰撞。
因此,设计者想了一个顾全大局的方法(综合考虑了速度、作用、质量),就是把高16bit和低16bit异或了一下。设计者还解释到因为现在大多数的hashCode的分布已经很不错了,就算是发生了碰撞也用O(logn)的tree去做了。仅仅异或一下,既减少了系统的开销,也不会造成的因为高位没有参与下标的计算(table长度比较小时),从而引起的碰撞。
- 得到的hash值和entry table的长度求余。
index = hash % n,因为entry table的长度为2的次幂,因此有
index = hash % n == hash & (n - 1) 定理:当n为2的次幂时,因为n-1的二进制除了第一位为0,其他各位都为1,而和1求&操作会保留原数。因此对任何正整数x,x % n == x & (n - 1)。
Resize实现
当put时,如果发现目前插入节点的数目已经超过了Load Factor比率限制的值,将发生resize,table的长度将扩展为原先的两倍,对每个节点重新计算index并移动。
由于table的长度始终为2的次幂,因此元素的新位置,要么是原index不变,要么是原index + OldCapacity。因此并不需要重新计算hash值,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话index没变,是1的话索引变成“原index+oldCapacity”。
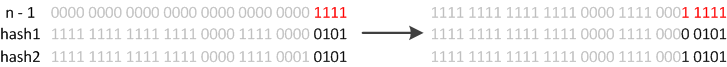
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。
问题小结
- HashMap的初始容量及扩容因子。
HashMap可以在初始化时指定初始容量和扩容因子,但是初始容量会被自动调整为大于等于给定值的2的次幂。如果没有指定,初始容量默认为16,扩容因子默认为0.75。
- HaspMap扩容是怎样扩容的,为什么都是2的N次幂的大小。
首先,HashMap初始大小就必须是2的次幂,由于hashMap通过hash值和bucket大小n-1的值进行与操作得到位置index,又由于n为2的次幂,每次扩容时bucket的长度又为原长度的两倍,从二进制的角度看就是正好多考虑了hash的一位,因此在计算新index时,不需要重新进行计算,直接查看原hash值,如果新考虑的一位是0,那么新的index和原来的index相同,如果新考虑的一位是1,那么新的index为原index加上原bucket长度。
- 为什么HashMap初始的capacity大小必须是2的次幂?
我们知道HashMap通过hash值对bucket的长度求余得到在buket上的index位置,在hashMap的实现中,利用了一个公理,及当n为2的次幂时,任何数对求余等于对n-1进行与操作。因为hashMap中计算index时使用与操作代替求余操作,因此初始的capacity大小必须是2的次幂,扩容也必须是原先容量的两倍。
- Java8中对HashMap进行了怎样的优化?
Java8中新增了一个阈值,当一个bucket中冲突元素的数目达到阈值时,将链表改为红黑树,降低了系统冲突时的时间要求,从O(n)降为O(lgn)。在Java8目前的实现中,阈值默认为8。
- HashMap中是否任何对象都可以做为key,用户自定义对象做为key有没有什么要求?
==必须重写equals和hashCode函数,key和value值可以是null,所以不能通过get返回nll判断键值对是否存在,要用containsKey。==
- HashMap是否是线程安全?为什么?
HashMap的各个操作没有使用任何锁机制,是线程不安全的。
-
HashMap线程不安全的具体表现
- 当多个线程同时put新的元素时,如果这两个元素映射到同一个bucket中,其中一个元素会被覆盖掉。
- 当多个线程put时,可能同时检测到HashMap中的元素个数超过了扩容因子限制的数目,同时对HashMap进行扩容。在多线程操作链表的指向时,容易造成循环链表。
问题
- 集合 HashMap 的原理,与 Hashtable、ConcurrentHashMap 的区别? 3.
- HashMap,HashTable,ConcurrentHashMap的区别。
- 极高并发下HashTable和ConcurrentHashMap哪个性能更好,为什么,如何实现的。
- HashMap 和 Hashtable 的区别
- HashSet 和 HashMap 区别
- HashMap 和 ConcurrentHashMap 的区别
- ConcurrentHashMap 的工作原理及代码实现
- HashMap和Hashtable的区别
- hashMap/hashTable/coccurentHashMap
- synchronized Map
- HashMap的工作原理,底层原理基本实现,初始容量及每次扩容因子,怎么解决碰撞问题的,jdk8做了怎样的优化。
refs:
- https://yikun.github.io/2015/04/01/Java-HashMap%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E5%8F%8A%E5%AE%9E%E7%8E%B0/
本文地址:https://cheng-dp.github.io/2018/06/17/HashMap/