CMS的特点
- 老年代
- 标记-清除算法(之前的都是标记-整理算法),产生内存碎片。
- 并发收集,低停顿时间,适用于用户交互多的场景。 CMS是HotSpot在JDK1.5推出额第一款真正意义上的并发(Concurrent)收集器==,第一次实现了让垃圾回收线程与用户线程同时工作==。
CMS的缺点
- 对CPU资源非常敏感。
其实,面向并发设计的程序都对CPU资源比较敏感。在并发阶段,它虽然不会导致用户线程停顿,但是会因为占用了一部分线程(或者说CPU资源)而导致应用程序变慢,总吞吐量会降低。 - 无法处理浮动垃圾
- 基于“标记-清除”算法,产生内存碎片。但是提供-XX:+UseCMSCompactAtFullCollection和-XX:CMSFullGCsBeforeCompaction参数控制执行内存碎片压缩。
参数
-XX:UseConcMarkSweepGC 显示使用CMS收集器
CMS的收集过程
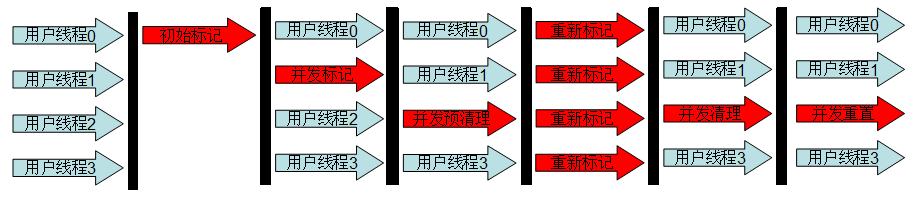
初始标记(CMS initial mark)
是CMS中两次Stop The World中的一次,标记存活的对象。
- 标记GC Roots可达的老年代对象。
- 遍历新生代对象,标记可达的老年代对象。
-XX:+CMSParallelInitialMarkEnabled
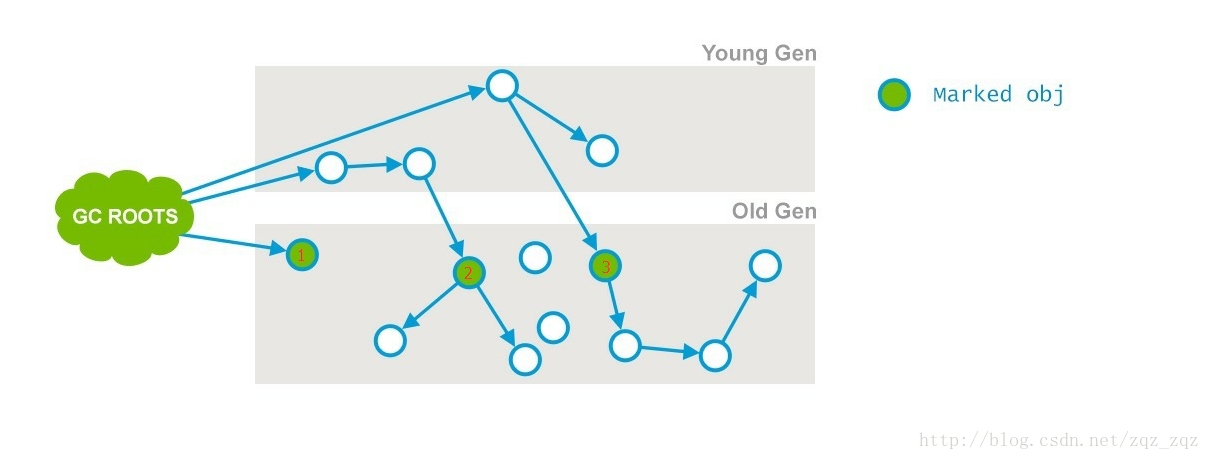
并发标记(CMS concurrent mark)

- 从初始标记阶段的对象开始找出所有存活的对象。
- 因为是和用户程序并发运行,在运行期间会发生新生代对象晋升到老年代、直接在老年代分配对象、更新老年代对象的引用关系等。需要重新标记这些对象,否则会出现漏标。为了提高重新标记的效率,避免之后要重新扫描整个老年代,在并发标记阶段,上述对象所在的Card会被标识为Dirty,后面的步骤中只需要重新扫描被标记为Dirty Card中的对象。
- 可能导致==Concurrent Mode Failure==。
Concurrent Mode Failure 在并发标记阶段,用户程序并行执行,不断有新对象被分配至老年代,如果此时老年代空间不足,就会造成Concurrent Mode Failure, ==CMS将退化成SerialOld==,单线程、Stop The World的对老年代对象进行一次回收。
Card Table 卡表
Card Table实质是一个比特位的集合,每一个比特位用来表示老年代的某一个区域。
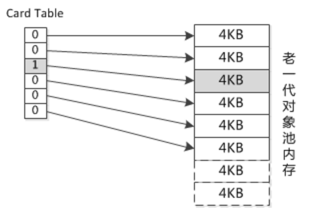
好处:不需要重新扫描整个老年代、节省时间,也不需要记录所有需要重新标记的对象,节省空间。
并发预清理阶段(Concurrent Preclean[non-abortable])
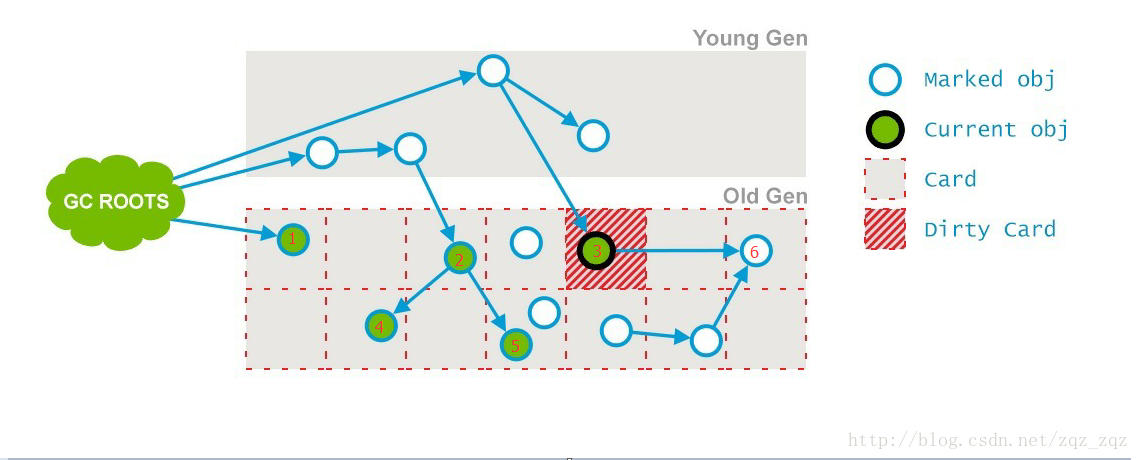
该阶段扫描所有标记为Dirty的card(新分配至老年代或老年代引用改变),处理前一个阶段因为引用关系改变导致没有标记到的存活对象。
如图中所示,在并发清理阶段,节点3的引用被改变,指向了节点6,则节点3的card标记为Dirty,节点6在预清理阶段被标记为存活。
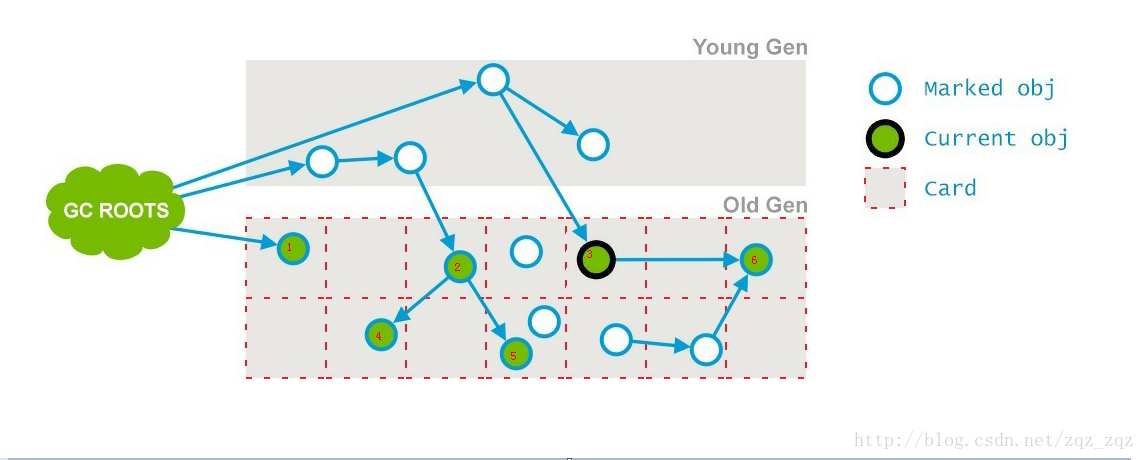
并发可终止预处理(Concurrent Abortable Preclean)
重新标记(Final Remark)会扫描整个新生代,并且需要Stop The World,因此,为了减少重新标记(Final Remark)的时间,在并发预清理阶段(Concurrent Preclean)结束后,如果新生代(Eden)大小超过CMSScheduleRemarkEdenSizeThreashold的值,进入并发可终止预清理阶段(Concurrent Abortable Preclean),并发地重复标记新生代和老年代,直到新生代(Eden)的大小超过CMSScheduleRemarkEdenPenetration,或者该阶段执行时间超过CMSMaxAbortablePrecleanTime,进入重新标记(Final Remark)阶段。
并发可终止预处理(Concurrent Abortable Preclean)阶段期望在执行过程中新生代(Eden)能够发生一次YoungGC,以大量减少重新标记(Final Remark)阶段需要扫描的工作量。
重新标记(Final Remark)
该阶段需要Stop The World,任务是完成标记老年代的所有存活对象。
该阶段也会扫描新生代,因为被新生代对象引用的老年代对象也需要标记为存活。
因此,所有上面步骤中标记的老年代,和所有引用了老年代的新生代对象,都会成为这一阶段的”GC Root”。
-XX:+CMSScavengeBeforeRemark,指定在重新标记阶段前执行一次young GC,这样只需要扫描Survivor区,大大减少了扫描时间。
并发清理(Concurrent Sweep)
并发回收没有被标记存活的老年代对象。
由于用户线程仍然在运行,==新的垃圾没有被标记==,只能在下一次GC时清理,这部分垃圾被称为浮动垃圾。
并发重置(Concurrent Reset)
重置CMS收集器的数据结构,等待下一次回收。
参数设置
| 基本参数 | 作用 |
|---|---|
| -XX:+UseConcMarkSweepGC | 开启CMS |
| -XX:CMSInitiatingOccupancyFraction=85 | 触发FullGC的老年代使用百分比 |
| -XX:+UseCMSCompactAtFullCollection | 在CMS执行FullGC后执行内存压缩,防止产生过多内存碎片 |
| -XX:CMSFullGCsBeforeCompaction=5 | 执行多少次FullGC后执行一次内存压缩 |
| -XX:ParallelGCThreads=8 | 并发标记和清除时的线程数 |
| -XX:CMSScheduleRemarkEdenSizeThreshold=2M | 启动并发可终止预处理(Concurrent Abortable Preclean)时的新生代大小阈值 |
| -XX:CMSScheduleRemarkEdenPenetration=50 | 结束并发可终止预处理(Concurrent Abortable Preclean)时的新生代已用大小百分比阈值 |
| -XX:CMSMaxAbortablePrecleanTime=5000 | 并发可终止预处理(Concurrent Abortable Preclean)最长运行时间(ms) |
| -XX:ScavengeBeforeRemark | 强制在并发清理(Concurrent Sweep)前执行一次YoungGC |
Full GC
导致CMS Full GC的可能原因有:
- Promotion Failure,年轻代晋升时老年代没有足够的连续空间容纳,很有可能是内存碎片导致。
- Concurrent Mode Failure,并发过程中JVM计算估计在并发过程结束前堆空间就会满。
refs:
- https://blog.csdn.net/zqz_zqz/article/details/70568819
- https://plumbr.eu/handbook/garbage-collection-algorithms-implementations/concurrent-mark-and-sweep
- https://blogs.oracle.com/poonam/understanding-cms-gc-logs
- http://www.importnew.com/27822.html
本文地址:https://cheng-dp.github.io/2018/12/03/gc-cms/