ZooKeeper是一个典型的发布/订阅模式的分布式数据管理与协调框架,开发人员可以使用它来进行分布式数据的发布与订阅。
另一个方面,通过对ZooKeeper中丰富的数据节点类型进行交叉使用,配合Watcher事件通知机制,可以非常方便地构建一系列分布式应用都会涉及的核心功能,如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等。
数据发布/订阅
发布者将数据发布到ZooKeeper的一个或一系列节点上,供订阅者进行数据订阅,进而达到动态获取数据的目的,实现配置信息的集中式管理和数据的动态更新。
ZooKeeper采用的是推(Push)拉(Pull)相结合的方式:客户端向服务端注册自己需要关注的节点,一旦该节点的数据发生变更,那么服务端就会向相应的客户端发送Watcher事件通知,客户端接收到这个消息通知后,需要主动到服务端获取最新的数据。
负载均衡(Load Balance)
负载均衡应用举例:DNS(Domain Name System)系统。
问题
需要在系统内部提供DNS服务,如在Company中提供app1.company.com和app2.company.com服务。实际开发中,使用本地HOST绑定来实现域名解析的工作。但是当机器规模变大后,需要在应用的每台机器上绑定域名,非常不便。
ZooKeeper实现
- 创建域名节点
如/DDNS/app1/server.app1.company.com。
每个应用都在ZooKeeper集群上创建自己的域名节点:/DDNS/app2/server.app2.company.com、/DDNS/app3/server.app3.company.com。
将负责该应用的服务器IP和端口集合保存在对应的域名节点中。
- 域名解析
DDNS方案中,域名解析过程是由每一个应用自己负责的,每个应用首先从对应的域名节点获取IP地址和端口,进行自行解析。
每个应用还会在域名节点上注册一个数据变更Watcher监听,以便及时收到域名变更通知,更新本地映射。
- 域名变更
在ZooKeeper集群上更新域名节点,应用会收到Watcher事件通知,并再次获取更新后的映射信息。
- 域名注册
提供一个Register集群专门负责自动域名注册。
应用启动时会向Register集群注册自己的域名,Register根据域名信息写入对应的ZooKeeper节点。
- 域名探测
提供一个Scanner集群负责检测服务器的状态,通过心跳检测或者服务器主动向Scanner定时汇报的方式。
如果Scanner判断某个服务器不可用时,主动更新ZooKeeper上对应的域名节点。
命令服务
在分布式系统中提供一个全局唯一ID。
为什么不用UUID ?
1. 长度太长,32个16进制字符(128位),转换为String为[32个字符+4个字符('-')] * 8。
2. 含义不明。
通过调用ZooKeeper节点创建API,可以创建一个顺序节点,并且在API返回值中会返回这个节点的完整名字,改名字就可以作为全局唯一ID。
在ZooKeeper中,每一个数据节点都能够维护一份子节点的顺序序列,当客户端对其创建一个顺序子节点的时候ZooKeeper会自动以后缀的形式在其子节点上添加一个序号。
如创建”job-“,会返回一个”job-000001”、”job-000002”…
分布式协调/通知
ZooKeeper能够保证数据在多个服务之间保持同步、一致,因此能够在服务之间共享状态变化,协调分布式操作。
心跳检测
通常的方式是服务器之间互相发送PING命令检测对方状态。
通过ZooKeeper可以使用临时节点,服务器在ZooKeeper的一个指定节点下创建临时节点,不同机器之间可以根据这个临时节点来判断对应的服务器是否存活。
工作进度汇报
每个子任务服务器在ZooKeeper指定节点上创建临时节点:
- 确定任务机器是否存活。
- 任务机器实时任务执行进度写到创建的临时节点,中心系统能够实时获取到任务执行进度。
系统调度
控制台不再向每个服务器发送命令,而是直接修改ZooKeeper上对应节点,服务器通过Watcher通知得到控制台发送的调度命令。
集群管理
利用ZooKeeper的两大特性实现集群管理:
- 客户端如果对ZooKeeper的一个数据节点注册Watcher监听,那么当该数据节点的内容或是其子节点列表发生变更时,ZooKeeper服务器就会向订阅的客户端发送变更通知。
- 对在ZooKeeper上创建的临时节点,一旦客户端与服务器之前的会话失效,那么该临时节点也就被自动清除。
同样也是通过临时节点实现集群机器的监控以及数据分发。
Master选举
在分布式环境中,经常需要选举出一个或多个领头节点,该节点具有对分布式系统状态变更的决定权。
ZooKeeper会保证客户端无法重复创建一个已经存在的数据节点。如果同时有多个客户端请求创建同一个节点,最终一定只有一个客户端请求能够创建成功。
ZooKeeper实现:
客户端同时向ZooKeeper对应节点上创建一个“临时节点”,在这个过程中,只有一个客户端能够成功创建,该客户端即称为Master。其他没有创建成功的客户端,将在对应节点上创建一个Watcher,一旦发现当前的Master挂了,其余的客户端可以开始重新进行Master选举。
分布式锁
在平时的项目中,可以依赖于关系型数据库固有的排他性实现进程之间的互斥,但是由于绝大多数分布式系统的性能瓶颈都在数据库操作上,因此,最好能够减少对于数据库的操作。
排他锁
通过临时节点实现。
- 定义锁
通过ZooKeeper上的数据节点来表示一个锁,如/exclusive_lock/lock。
- 获取锁
所有获取锁的客户端调用create()接口,在/exclusive_lock下尝试创建/exclusive_lock/lock。
最终只有一个客户端能够创建成功,认为该客户端获取了锁,没有获取到锁的客户端对/exclusive_lock注册子节点变更的Watcher监听。
- 释放锁
- 获取锁的客户端正常执行完任务后,主动删除创建的临时节点。
- 获取锁的客户端宕机,ZooKeeper将移除该临时界定啊。
子节点移除后,注册了Watcher监听的其他客户端将受到通知,重新发起分布式锁的获取。
共享锁(读写锁)
通过临时顺序节点实现。
实现一
- 定义锁
同样是ZooKeeper上的数据节点表示一个锁:临时顺序节点 –> /shared_lock/[HostName]-请求类型-序号。
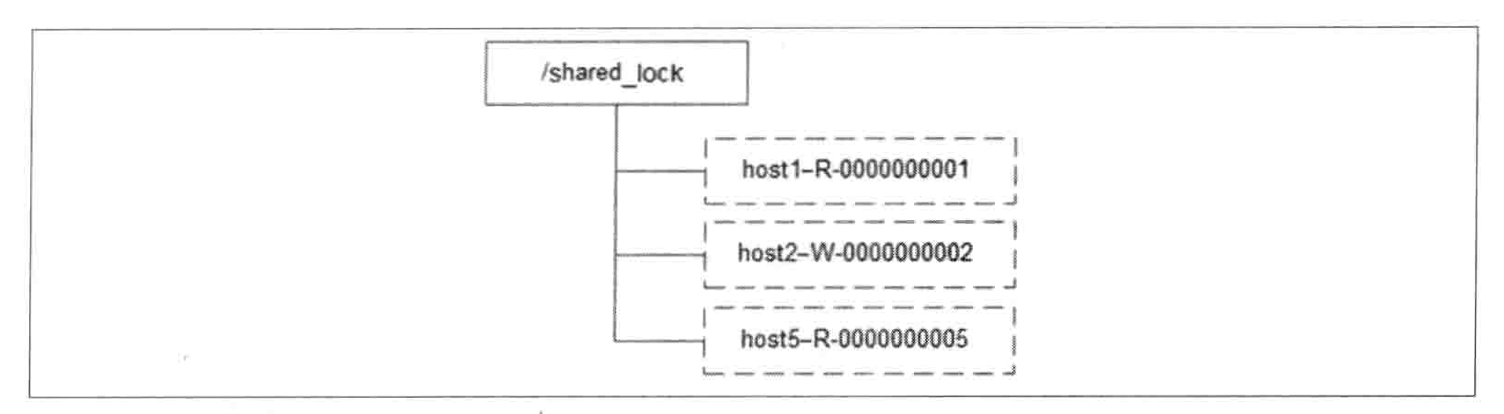
- 获取锁
所有客户端在/shared_lock节点下创建临时顺序节点:
- 读请求 –>
/shared_lock/192.168.0.1-R-0000000001 - 写请求 –>
/shared_lock/192.168.0.1-W-0000000001
获取所有/shared_lock下的子节点,并对该节点注册子节点变更的Watcher监听。
==每次节点变动时重新获取/shared_lock下的子节点列表,确定自己的节点序号在所有子节点中的顺序。==
对于读请求:
- 如果比自己序号小的子节点中有写请求,则等待。
- 如果比自己序号小的子节点都是读请求,或没有比自己序号小的子节点,则执行读逻辑。
对于写请求:
- 如果有比自己序号小的子节点(不是最小),则等待
- 释放锁
删除自己定义的子节点。
羊群效应
[实现一]有一个问题,及羊群效应。每个客户端都对节点/shared_lock注册了Watcher事件,即当每个子节点失效时,ZooKeeper会向所有的客户端发送大量的事件通知,然而绝大多数的客户端运行结果都是判断出自己并非是序号最小的节点,从而等待下一次通知。也就是实际上大部分客户端都无缘无故地接收到过多和自己并不相关的事件通知。
解决方法:
- 在尝试获取锁失败后,获取所有已经创建的子节点列表。
- 找到比自己小的那个节点(读请求找到更小的最后一个写请求节点,写请求找到前一个节点)。
- ==对该节点注册Watcher通知。==
分布式队列
FIFO队列
FIFO队列的实现类似于一个全写的共享锁模型。
- 所有客户端在
/queue_fifo节点下创建临时顺序节点。 - 获取
/queue_fifo所有子节点。 - 判断自己是否是序号最小的子节点,如果不是,向比自己小的最后一个节点注册
Watcher监听,进入等待。 - 接收到Watcher通知后,重新获取所有子节点并判断。
Barrier屏障
屏障规定只有当所有元素都集聚后才能继续。
- 创建
/queue_barrier节点,节点数据值为屏障需要的元素个数。 - 所有客户端到
/queue_barrier节点下创建临时子节点。 - 创建完后,判断目前子节点个数是否等于
/queue_barrier节点值,并注册/queue_barrier的Watcher通知。 - 如果不等,则进入等待。如果等则继续执行。
- 收到Watcher通知后,重复检查子节点个数。
本文地址:https://cheng-dp.github.io/2019/04/06/zookeeper-usages/