生产者消息发送流程
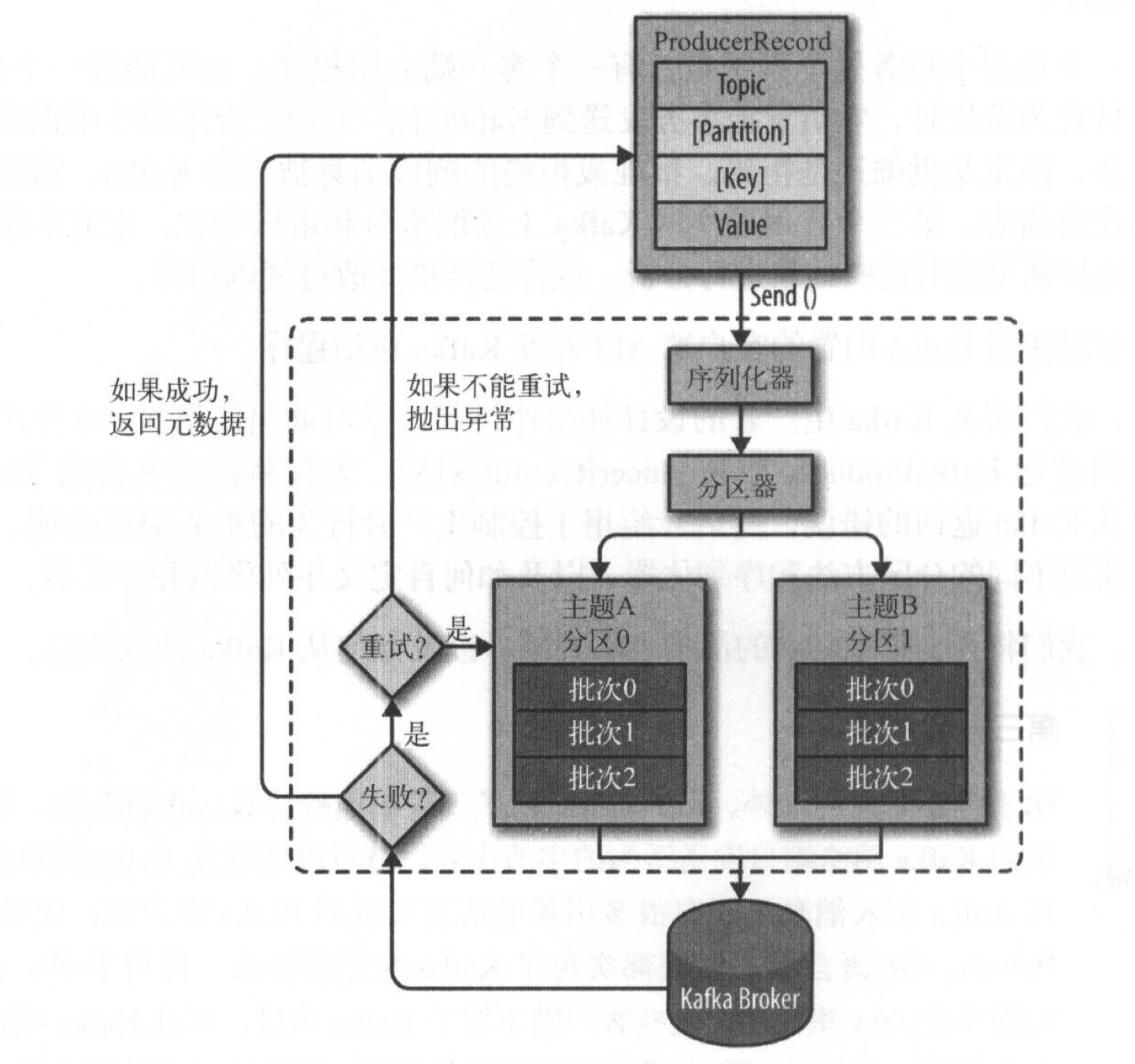
- 创建ProducerRecord对象,包含目标主题和要发送的内容。可以指定键或分区。
- 生产者把键和值对象序列化成字节数组。
- 如果ProducerRecord指定了分区,分区器直接返回该分区,如果没有指定分区,分区器根据ProducerRecord对象的键选择一个分区。
- 记录被添加到对应主题和分区的记录批次中,有一个独立的线程负责把记录批次发送到相应broker上。
- 服务器收到消息返回响应。如果成功写入Kafka,返回一个RecordMetaData对象,包含主题和分区信息、以及记录在分区中的偏移量。失败则返回错误。
创建生产者
创建Kafka生产者对象,设置3个必选属性:
- bootstrap.servers
指定Kafka broker地址清单,地址的格式为host:port,不需要包含所有broker地址,生产者会从给定broker里查找到其他broker的信息。
建议至少提供两个broker的信息,一旦其中一个宕机,生产者仍然能够连接到集群上。
- key.serializer
数据需要被序列化为字节数组,key.serializer必须被设置为一个实现了org.apache.kafka.common.serialization.Serializer接口的类。
- value.serializer
与key.serializer相同。
发送消息举例:
private class DemoProducerCallback implements Callback {
@Override
public void onCompletion(REcordMetadata recordMetadata, Exception e) {
if (e != null) {
e.printStackTrace();
}
}
}
ProducerRecord<String, String> record = enw ProducerRecord<>("TestTopic", "TestKey", "TestValue");
producer.send(record, new DemoProducerCallback());
生产者的配置
- acks
指定必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。
acks=0, 生产者不等待任何服务器响应,不关心发送结果,吞吐量最大。
acks=1, 只要集群首领收到消息,生产者就会收到来自服务器的成功响应。
acks=all,只有当全部参与复制的节点收到消息时,生产者才会收到来自服务器的成功响应。
- buffer.memory
设置生产者内存缓冲区的大小。
- compression.type
设置消息发送时压缩方式(snappy/gzip/lz4),默认不压缩。
- retries
生产者从服务器收到临时性错误(如分区找不到首领)时,重试的次数。
- batch.size
多个消息需要被发送到同一个分区时,生产者会把他们放在同一个批次里。
指定批次可以使用的最大内存大小(字节数)。当批次被填满时,批次里所有消息会被发送出去。
生产者并不一定都会等到批次被填满才发送,见linger.ms。
- linger.ms
设置生产者在发送批次之前等待更多消息加入批次的时间。
当批次填满或linger.ms达到上限时,Kafka会发送批次。
linger.ms默认为0,即不等待,就算批次里只有一个消息也立即发送。
- client.id
生产者客户端id。
- max.in.flight.requests.per.connection
指定了生产者在收到服务器响应之前可以发送多少个消息。
- timtout.ms、request.timeout.ms、metadata.fetch.timtout.ms
指定了生产者等待服务器返回响应的时间。
- max.block.ms
设置在调用send()方法或partitionsFor()方法时生产者的阻塞时间。当生产者发现缓冲区已满,方法会阻塞,阻塞达到max.block.ms时,生产者会抛出异常。
- max.request.size
控制生产者发送的请求大小。
- receive.buffer.bytes 和 send.buffer.bytes
设置TCP socket接收和发送数据包的缓冲区大小,-1为使用操作系统默认值。
生产者消息的顺序
Kafka可以保证同一个分区里成功发送的消息是有序的。即如果生产者按照一定的顺序成功发送消息,broker就会按照这个顺序把他们写入分区,消费者也会按照同样的顺序读取它们。
如果retries大于零,同时max.in.flight.requests.per.connection设为比1大的数,那么,如果前一个批次消息写入失败,后一个批次写入成功,接着broker重试写入第一个批次,如果重试成功,则两个批次顺序倒转。
==所以,如果对消息顺序性有严格要求,可以把max.in.flight.requests.per.connection设为1。==
键的分区
-
拥有相同键的消息将被写到同一个分区。
-
==如果键值为null,并且使用了默认的分区器,分区器将使用轮询(Round Robin)算法将消息均衡地分布到各个分区上。==
-
如果键不为空,并且使用了==默认的分区器,Kafka会对键进行散列==,根据散列值将消息映射到特定的分区上。
-
==Kafka使用自己的散列算法,只有在不改变主题分区数量的情况下,键与分区之前的映射才能保持不变。==
-
可以实现Partitioner接口,实现自己定义的分区策略,将特定key映射到特定分区上。
本文地址:https://cheng-dp.github.io/2019/04/18/kafka-producer/