集群成员关系
Kafka使用ZooKeeper维护集群成员的信息,每个broker有唯一的ID,并在启动时创建临时节点把自己的ID注册到ZooKeeper /brokers/ids路径。
Kafka组件订阅ZooKeeper的/brokers/ids路径,可以获得broker创建或宕机的通知。
关闭broker时,它的ID从ZooKeeper上删除,但是继续存在于其他数据结构中(如:主题的副本列表),完全关闭一个broker后,如果使用相同的ID启动另一个全新的broker,它会立即加入集群,并拥有与旧broker相同的分区和主题。
控制器(Controller)
控制器是一个broker,除了一般broker的功能外,还负责==分区首领的选举==。
集群里的broker通过在Zookeeper创建临时节点/controller竞争成为控制器。其他broker创建失败后会向/controller节点注册watch对象。
当前控制器宕机后,其他broker会收到watch消息,并尝试创建/controller竞争称为新的控制器。
每个新选出的控制器通过Zookeeper的条件递增操作获得一个新的controller epoch, 其他broker在知道当前controller epoch后,会忽略之前控制器发出的包含较旧epoch的消息。
复制
Kafka是一个分布式的、可分区的、可复制的提交日志服务。
Kafka使用主题来组织数据,每个主题分为若干个分区,每个分区有多个副本。
==副本保存在broker上,每个broker可以保存属于不同主题和分区的多个副本。==
- 首领副本
每个分区只有一个首领副本,所有生产者请求和消费者请求都经过该副本。
- 跟随者副本
除首领副本外都是跟随者副本。跟随者副本不处理来自客户端的请求,唯一的任务就是从首领那里复制消息,保持与首领一致的状态。如果首领副本所在的broker崩溃,其中的一个跟随者将成为新首领副本。
- 跟随者副本—同步的副本
跟随者向首领发送和消费者一样的,获取数据的请求,请求包含有序的偏移量。只有收到前一个偏移量请求的回复后,才会继续请求下一个偏移量的请求。
==通过查看每个跟随者请求的偏移量,首领就会知道每个跟随者复制的进度。==如果跟随者在10s内没有请求任何消息、或者虽然在请求消息,但在10s内没有请求最新的数据,就被认为是不同步的。
持续请求得到最新消息的副本被称为同步的副本,==只有同步的副本才能被选为新首领。==
分区首领副本的选举
Kafka在ZooKeeper上为每个Topic维护一个所有==同步副本的集合==,称为ISR(In-Sync Replica)。
当Leader分区不可用时,控制器(Controller)broker直接从ISR列表中取出第一个broker作为新的首领,如果不行则依次类推。
处理请求
Kafka提供了一个二进制协议(基于TCP),指定了请求消息的格式以及broker如何对请求做出响应。客户端发起连接并发送请求,broker按请求到达的顺序处理请求并做出响应。
标准消息头:
- Request type : API key
- Request version : broker可以处理不同版本的客户端请求,根据客户端版本做出不同响应。
- Correlation ID : 标识请求消息。
- Client ID : 表示发送请求的客户端。
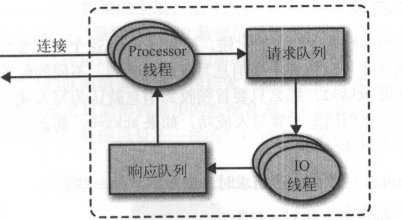
broker请求处理流程:
- brokerAcceptor线程监听端口,创建连接并交给Processor线程。
- Processor线程将客户端请求放入请求队列、从响应队列获取响应消息发给客户端。
常见的请求类型:
- 生产请求
生产者向broker发送要写入的消息。
- 获取请求
消费者和跟随者从broker读取消息。
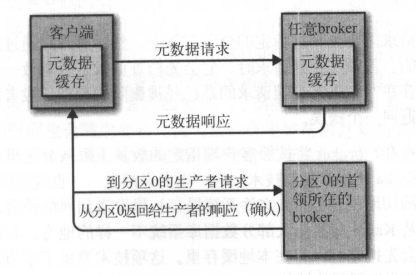
- 元数据请求
==生产请求和获取请求都必须发送给分区的首领副本==,如果broker收到一个针对特定分区的请求,而该分区的首领在另一个broker上,那么发送请求的客户端会收到一个 ==“非分区首领”== 错误。因此,客户端需要利用元数据请求知道生产和获取请求的目标broker。
客户端向服务器请求感兴趣的主题列表信息,服务端的响应消息里指明了主题包含的分区、每个分区有哪些副本、哪个副本是首领副本,副本所在的broker。
元数据请求可以发送给任意一个broker,因为所有broker都缓存了所有主题的元数据。
客户端会定期发送(metadta.max.age.ms)元数据请求刷新主题分区信息,并将这些元数据缓存在本地。
生产请求
- 请求验证
broker收到生产请求,对请求做验证:
- 发送数据的用户是否有主题写入权限?
- 请求包含的acks值是否有效?(0, 1, all) ?
- 如果acks = all, 是否有足够多的同步副本保证消息已经被安全写入 如果此时同步副本数目小于配置,broker可以拒绝处理新消息。
- 消息写入
验证后,消息将被写入本地磁盘(文件系统缓存),并不保证何时刷新到磁盘上,Kafka不会一直等待数据被写到磁盘上,它依赖复制功能来保证消息的持久性。
- 检查acks参数并返回
==如果acks=0或1, broker立即返回响应,如果acks=all,请求将被加入缓冲区,直到首领发现所有跟随者副本都复制了消息,才向客户端返回响应。==
获取请求
客户端向broker请求主题分区里特定偏移量的消息:
把
主题Test,分区0,偏移量从53开始,的消息
以及
主题Test,分区3,偏移量从64开始,的消息
发给我
- 客户端可以指定broker最多从一个分区里返回的数据上限。
如果没有这个限制,broker返回大量数据有可能耗尽客户端的内存。
- 客户端也可以指定broker返回数据的下限。
即broker将等到有足够的数据量时,才返回给客户端。同时,客户端可以定义一个超时时间,当等到超时时间到达时,即使没有足够的数据量,broker也将返回。
- broker检查请求是否有效。
如,指定的偏移量在分区上是否存在,如果检查失败返回错误。
- broker向客户端发送数据。
==Kafka使用零复制技术向客户端发送消息==,直接把消息从文件(文件系统缓存)中发送到网络通道,不经过中间缓冲区。
- 大部分客户端只能读取已经被写入所有同步副本的数据。
还没有足够多副本复制的消息被认为是不安全的,如果首领发生崩溃,这些消息可能丢失。
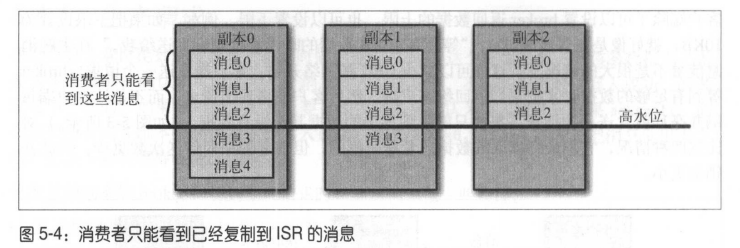
如果broker间的消息复制变慢,那么消息到达消费者的时间也会变长。
消息存储
Kafka的基本存储单位是分区(Partition)。
分区分配
==在创建主题时,Kafka首先会决定如何在broker间分配分区。==
分配目标:
- 在broker间平均地分布分区副本。
- 确保分区的不同副本分布在不同的broker上。
- 如果为broker指定了机架信息(或机房信息),尽可能把每个分区的副本非配到不同机架的broker上。
分配过程:
假设有6个broker,创建包含10个分区的主题,复制系数为3,也就是有30个分区副本。
- 从随机的broker开始,使用轮询的方式分配首领分区。
随机选中broker 4,则首领0分配在broker 4, 首领1分配在broker 5, 首领2分配在broker0 (broker为0-5)... - 从分区首领开始,依次分配跟随者副本。
如首领0分配在broker4,则跟随者0在broker 5,跟随者1在broker0...
如果配置了机架信息,就不是轮询broker ID,而是轮询机架ID。
为分区副本分配broker目录:
计算每个目录里的分区数量,新的分区总是被添加到分区数量最小的那个目录里。
消息文件
文件管理
Kafka管理员能为每个主题配置数据保留期限,规定数据被删除之前可以保留多长时间,或者保留的最大数据量大小。
==分区(Partition)被分成若干个片段(Segment),默认为1G,达到片段上线,就关闭当前文件并打开一个新文件。==
当前正在写入的片段文件叫做活跃片段,活跃片段永远不会被删除。
文件格式
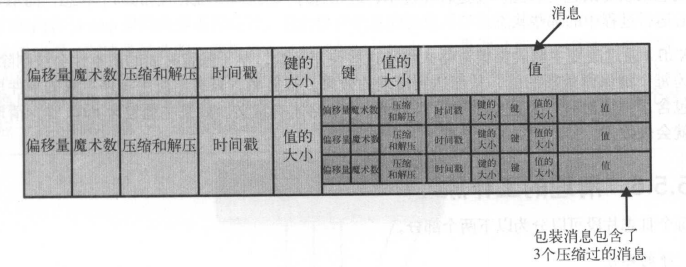
==Kafka保存在文件的消息格式与生产者发送以及发送给消费者的格式一致。==
==因为使用了相同的消息格式进行磁盘存储和网络传输,Kafka可以使用零复制技术,同时避免在broker上对生产者压缩过的消息进行解压和再压缩。==
如果生产者发送的是压缩过的消息,那么同一个批次的消息会被压缩在一起,被当做“包装消息”发送,broker将直接记录压缩消息,然后再整个批次发送给消费者。
索引
Kafka broker需要迅速定位消费者要读取的偏移量位置,因此Kafka为每个分区维护了一个索引。把偏移量映射到片段文件和偏移量在文件里的位置。
索引也被分成片段,在删除消息时,也可以删除相应的索引。索引由Kafka读取消时自动生成,因此如果损坏或删除,Kafka都会自动重新生成。
消息清理
清理策略:
log.cleanup.policy=delete / compact
- delete 策略
根据设置的时间保留数据,把超时的旧数据删除。
- compact 策略
为每个键保留最新的值,删除旧值。
无论是delete策略还是compact策略都不会清理当前活跃片段。
清理工作原理
每个broker启动一个清理管理器线程和多个(log.cleaner.threads)清理线程, 清理线程每隔一定时间(log.retention.check.interval.ms)检查是否有日志需要清理, 清理线程每次选择dirtyRatio较高的分区进行清理。
delete策略
- 基于日志文件总大小(空间维度)
参数:
log.retention.bytes: broker级别(默认-1,未开启)retention.bytes: topic级别(默认-1,未开启)
清理线程比较 [当前日志总大小] - [阈值] >= [日志段大小],及当前所有日志段总大小是否比阈值大至少一个日志段大小,如果是,则从最老的日志段开始删除。
删除的最小单位是日志段。
- 基于日志分段最新修改时间(时间维度)
检查当前日志分段文件最新修改时间,删除和当前时间差值超过设定的时间阈值的日志段。
参数:
- log.retention.hours=168
- log.retention.minutes=null
- log.retention.ms=null
- 基于分区日志起始偏移量
如果日志段的下一个偏移量(end + 1)小于设置的起始偏移量,则删除。
compact策略
log.cleaner.enable=true
log.cleanup.policy=compact
每个日志片段(segment)分为两个部分:
- 干净(clean)的部分:之前已经被清理过。
- 污浊(dirty)的部分:在上一次清理后写入的消息。
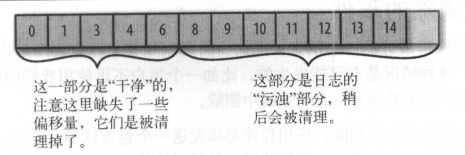
==清理线程从dirtyRatio较高的分区进行清理,维护一个map,对每一个key,只保留最新值,删除就版本的数据。==
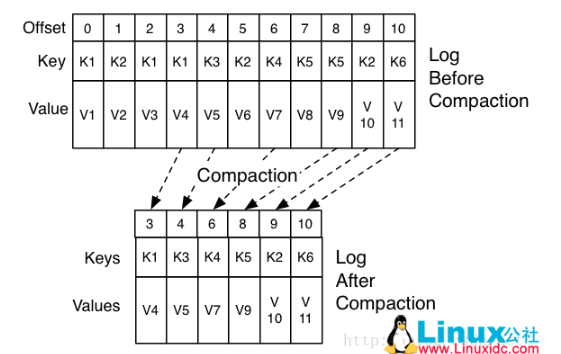
==删除完成后,偏移量可能是不连续的。==
compact策略只适合对每个key的旧值不关心的特殊场景,如key是用户ID,value是用户的资料,整个消息集里只需要保存用户的最新资料。
compact策略下的删除:
==如果需要删除key最新的值,可以向broker发送值为null的消息(墓碑消息),broker首先会进行常规清理,删除null之前的消息,之后,null值消息会被保存一段时间后删除。==
本文地址:https://cheng-dp.github.io/2019/04/22/kafka-broker-manager-and-data-manager/