InnoDB关键特性
- 插入缓冲(Insert Buffer)
- 两次写(Double Write)
- 自适应哈希索引(Adaptive Hash Index)
- 异步IO(Async IO)
- 刷新领接页(Flush Neighbor Page)
Double Write 二次写
解决的问题
InnoDB的最小数据读写单位是数据页(Page),一般是16KB。
而操作系统写磁盘是按照扇区为基本单位,一个扇区通常为512B。
在极端情况下,如16KB数据写入4KB后断电,此时造成页数据错误,即Partial Page Write问题。
Redo Log根据Page头信息(如LSN)对页数据进行恢复,然而由于Partial Page Write问题,Page数据已经损坏,无法确定Page头信息,因此无法根据Redo Log恢复。
Double Write流程
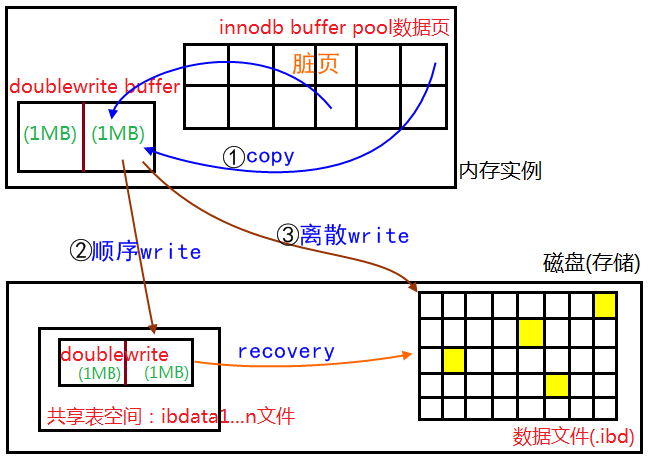
Double Write有两部分组成:
- 内存中的Double Write Buffer,大小为2MB。
- 磁盘上的共享表空间(ibdata)中连续128个页,大小也为2MB。
为了解决Partial Page Write的问题,在将Buffer Pool中的脏页写回磁盘数据未见时:
- 脏页不直接写入磁盘数据文件,而是先拷贝(memcopy)至内存中的Double Write Buffer。
- 从Double Write Buffer中分两次写入磁盘共享表空间中,每次写1MB (连续存储,顺序写,性能很高)。
- 2完成后,再将Double Write Buffer中的脏页数据写入实际各个数据文件中。
在3中,当发生Partial Page Write问题时,可以直接从2中共享表空间中恢复数据。
1. 为什么 Redo Log/Undo Log不需要Double Write技术?
因为Redo Log/Undo Log每次写入磁盘的单位就是512字节,和磁盘IO最小单位相同,因此没有Partial Page Write问题。
2. 为什么不直接从Double Write Buffer写入数据文件?
double write里面的数据是连续的,如果直接写到data page里面,而data page的页又是离散的,写入会很慢。
Double Write缺点
在共享表空间上的Double Write数据也位于物理文件中,写共享表空间会导致系统有更多的fsync操作,降低MySQL的性能。
但是性能降低并不会非常明显,因为:
- 共享表空间上的Double Write空间是一个连续的空间,在写数据时是顺序添加的,不是随机写,性能很高。
- 将数据从Double Write写到数据文件时,InnoDB会对数据进行合并,增加每次写入刷新的页数。
Insert Buffer 插入缓冲
解决的问题
为了减少随机读写带来的性能损耗,通过Insert Buffer将辅助非唯一索引(Non-unique Secondary Index)的数据缓存下来,大幅度提高非唯一辅助索引的插入性能。
InnoDB中,Insert Buffer只适用于辅助非唯一索引,原因如下:
- 聚集索引(primary key)一般是按照主键递增的顺序插入的,所以通常是顺序的,不需要随机读取,插入速度很快。
- 如果是唯一索引,则在插入时需要首先读取辅助索引页,判断插入索引是否唯一,依然要进行随机读取。 因此,InnoDB中,只有辅助非唯一索引(Non-unique Secondary Index)才会使用Insert Buffer。
Insert Buffer原理
Insert Buffer插入流程:
- 首先判断被修改行所在页是否在内存缓冲池(Buffer Pool)中,如果在缓冲池中则直接插入缓冲池。
- 如果不在缓冲池中,则将数据插入Insert Buffer。
- 后台线程按照合并规则将Insert Buffer中的数据Merge回辅助索引页中,Merge会将Insert Buffer中的数据先进行合并,减少磁盘的离散读取,将多次插入合并为一次操作。
Insert Buffer能够缓存的操作可以是INSERT,UPDATE,DELETE(DML),最初只能缓存insert操作,所以叫Insert Buffer,现在已经改名为Change Buffer。
Merge合并规则:
- 辅助索引页被读取到缓冲池时。
- 当检测到目标辅助索引页可能空间不够时。
- Master Thread线程每秒或每10秒进行一次合并。
Insert Buffer合并举例:
name字段的插入顺序为:
('Maria',10), ('David',7), ('Tim', 11), ('Jim', 7), ('Monty', 10), ('Herry', 7), ('Heikki', 7)
在insert buffer中,记录根据应插入辅助索引的叶子节点page_no进行排序:
('David',7), ('Jim', 7), ('Herry', 7), ('Heikki', 7) , ('Maria',10), ('Monty', 10), ('Tim', 11)
当要进行合并时,页page_no为7的记录有4条,可以一次性将这4条记录插入到辅助索引中,从而提高数据库的整体性能。
Insert Buffer实现
Insert Buffer并不是内存缓存,而是物理页,存在于共享表空间(ibdata)中,按照B+树的方式组织数据。
试图通过独立表空间ibd文件恢复表中数据时,往往会导致check table失败。
这是因为表的辅助索引中的数据可能还在insert buffer中,也就是共享表空间中。
所以通过idb文件进行恢复后,还需要进行repair table 操作来重建表上所有的辅助索引。
InnoDB对Insert Buffer也做了缓冲,因此缓冲池(Buffer Pool)中也有Insert Buffer,按照回写条件回写至磁盘共享表空间。
因此插入Insert Buffer也可能是插入到缓冲池中。
在MySQL 4.1之前每张表有一颗Insert Buffer B+树。而目前版本全局只有一颗Insert Buffer B+树,存在于共享表空间(ibdata)中,负责所有表的辅助索引缓存。
Insert Buffer的B+树也是由叶子节点和非叶子节点组成。非叶子节点存放查询的Search Key:

- space:待插入记录所在的表空间id。
- marker:用来兼容老版本Insert Buffer。
- offset:页所在的偏移量。
插入辅助索引数据时,首先将构造一个Search Key,再查询B+树,插入到叶子节点中:
 -metadata:记录一些维护Insert Buffer的元数据,如记录插入的顺序,对应辅助索引页的剩余孔空间等。
-metadata:记录一些维护Insert Buffer的元数据,如记录插入的顺序,对应辅助索引页的剩余孔空间等。
由于Insert Buffer的B+树中,数据按照表空间和页所在偏移量排序,所以在Merge回辅助索引时能够很快地将属于相同页的数据合并一次插入。
Insert Buffer 缺点
插入缓冲主要带来如下两个坏处:
-
可能导致数据库宕机后实例恢复时间变长。如果应用程序执行大量的插入和更新操作,且涉及非唯一的聚集索引,一旦出现宕机,这时就有大量内存中的插入缓冲区数据没有合并至索引页中,导致实例恢复时间会很长。
-
在写密集的情况下,插入缓冲会占用过多的缓冲池内存(Buffer Pool),默认情况下最大可以占用1/2,这在实际应用中会带来一定的问题。
自适应哈希索引(Adaptive Hash Index, AHI)
InnoDB通过自使用哈希索引(Adaptive Hash Index)来加速对索引的访问。在InnoDB中,索引默认是一个B+树,InnoDB会对表上各索引页的查询进行监控,并对频繁访问的索引建立哈希索引。
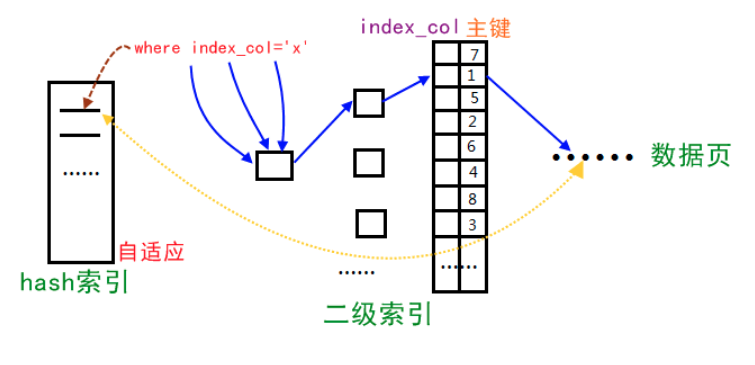
自适应哈希索引通过缓冲池的B+树构造而来,建立速度很快。取部分索引值前缀作为Hash key,value为数据页上的位置,大大节省了B+树中Search Path查找的过程。
建立自适应哈希索引的条件及问题:
- 重复访问某一特定查询模式达到一定数量才会创建,如
WHERE a = XXX,WHERE a = xxx and b = xxx。 - 只支持等值查询
=和IN,不支持LIKE, REGEXP等。 - 存在内存中,占用缓冲池资源(Buffer Pool)。
- 无法人为干预,只能配置开关:
set global innodb_adaptive_hash_index=off/on。
查看当前状态:
mysql> show engine innodb status;
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 276671, node heap has 0 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
REFS
DOUBLE WRITE:
- https://www.cnblogs.com/chenpingzhao/p/4876282.html
- https://www.cnblogs.com/chenpingzhao/p/4883884.html
INSERT BUFFER https://blog.csdn.net/Linux_ever/article/details/61639730 https://www.cnblogs.com/yuyue2014/p/3802779.html https://www.cnblogs.com/chenpingzhao/p/4883884.html https://www.zhihu.com/question/278406940
本文地址:https://cheng-dp.github.io/2019/05/05/innodb-three-feature/