索引分类
- INDEX 普通索引
最基本索引,允许出现相同的索引值,可以有NULL值。
- UNIQUE 唯一索引
不可以出现相同的值,可以有NULL值。
- PRIMARY KEY 主键索引
不允许出现相同的值,且不能为NULL值,一个表只能有一个primary_key索引。
- fulltext index 全文索引
上述三种索引都是针对列的值发挥作用,但全文索引,可以针对值中的某个单词,比如一篇文章中的某个词,然而只有myisam以及英文支持,并且效率较低,但是可以用coreseek和xunsearch等第三方应用来完成这个需求。
索引CRUD
- 索引创建
ALTER TABLE
ALTER TABLE `table_name` ADD INDEX `index_name` (`column_list`) --索引名,可要可不要;如果不要,当前的索引名就是该字段名。
ALTER TABLE `table_name` ADD UNIQUE (`column_list`)
ALTER TABLE `table_name` ADD PRIMARY KEY (`column_list`)
ALTER TABLE `table_name` ADD FULLTEXT KEY (`column_list`)
CREATE TABLE
CREATE TABLE `test1` (
`id` smallint(5) UNSIGNED AUTO_INCREMENT NOT NULL, -- 注意,下面创建了主键索引,这里就不用创建了
`username` varchar(64) NOT NULL COMMENT '用户名',
`nickname` varchar(50) NOT NULL COMMENT '昵称/姓名',
`intro` text,
PRIMARY KEY (`id`),
UNIQUE KEY `unique1` (`username`), -- 索引名称,可要可不要,不要就是和列名一样
KEY `index1` (`nickname`),
FULLTEXT KEY `intro` (`intro`)
) ENGINE=MyISAM AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='后台用户表';
CREATE INDEX
--例:只能添加这两种索引
CREATE INDEX index_name ON table_name (column_list)
CREATE UNIQUE INDEX index_name ON table_name (column_list)
- 索引删除
```
DROP INDEX
index_nameONtalbe_name
ALTER TABLEtable_nameDROP INDEXindex_name– 这两句都是等价的,都是删除掉table_name中的索引index_name;
ALTER TABLE table_name DROP PRIMARY KEY – 删除主键索引,注意主键索引只能用这种方式删除
3. 索引更改
直接删除索引后重建。
4. 查看table中的所有索引
show index from tablename;

## 索引限制
1. 一张表最多建立64个索引。
2. 组合索引最多包括16个列。
3. 单列索引长度
当`INNODB_LARGE_PREFIX=OFF`时,单列索引长度最大为767字节。
当`INNODB_LARGE_PREFIX=ON`时,单列索引长度最大为3072字节(1024*3)。
**为什么是767字节?**
256*3 - 1 = 767字节。3为utf-8字符最大占用空间。
4. 组合索引长度
组合索引长度最大为3072字节。
**为什么是3072字节?**
InnoDB一个Page默认16KB,由于是B+Tree,叶子节点上一个页至少包含两条记录(否则退化为链表),因此一条记录最大为8KB。
InnoDB的聚簇索引结构,一个二级索引要包含主键索引,因此单个索引最大为4KB。
单个索引空间再减去一些辅助空间,最大为3500字节,取整数为1024×3 = 3072字节。
## 索引实现
### 磁盘预读与页
由于磁盘存储介质的特性,磁盘本身存储比主存慢很多,为了提高效率,磁盘利用数据的局部性原理,每次进行I/O读取时,不仅仅只是读取数据字节,而是将数所在的页都读取进磁盘。及磁盘存储是以页(Page)为单位的。
### 为什么使用B+树
**B树**中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(log_dN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3),用**B树**作为索引结构效率是非常高的。
而**红黑树**这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比**B树**差很多。
从上面分析可以看到,d越大索引的性能越好,而出度的上限取决于节点内key和data的大小:
```math
(d_{max}=floor(pagesize / (keysize + datasize + pointsize)))
floor表示向下取整。由于B+Tree内节点去掉了data域,因此可以拥有更大的出度,拥有更好的性能。
MyISAM索引实现
MyISAM引擎B+树中,叶子节点的data域存放的是数据记录的地址。
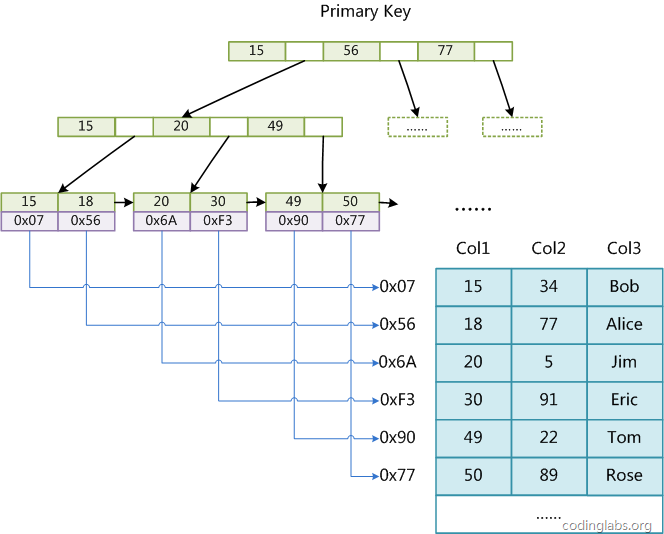
辅助索引和主索引结构上没有任何区别,只是主索引要求Key是唯一的,而辅助索引的Key可以重复。
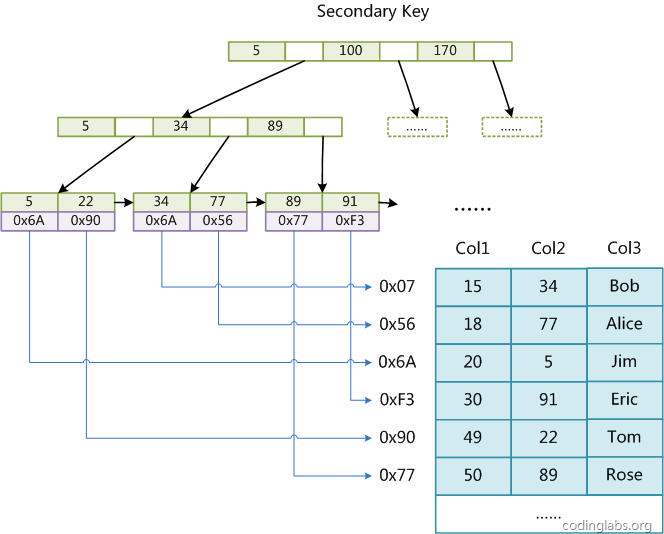
MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM索引实现的方式称为非聚集索引,以此与InnoDB的聚集索引区分。
InnoDB索引实现
MyISAM引擎索引文件和数据文件分离,而在InnoDB中,表数据文件本身就是按B+树组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。
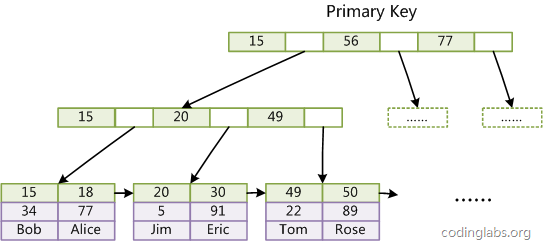
InnoDB中B+树叶节点按照主键聚集,包含了完整的数据记录,这种索引叫做聚集索引。
InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
==InnoDB的辅助索引data域存储相应记录主键的值而不是地址。==
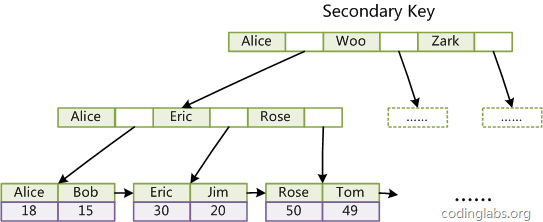
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
组合索引、前缀索引和最左前缀原理
组合索引
多个列共同组合成一个索引,MySQL查询时对组合索引执行最左前缀查询。
ALTER TABLE `myIndex` ADD INDEX `name_city_age` (vc_Name(10),vc_City,i_Age);
会用到组合索引:
SELECT * FROM myIndex WHREE vc_Name=”erquan” AND vc_City=”郑州”
SELECT * FROM myIndex WHREE vc_Name=”erquan”
不会用到组合索引:
SELECT * FROM myIndex WHREE i_Age=20 AND vc_City=”郑州”
SELECT * FROM myIndex WHREE vc_City=”郑州”
前缀索引
如果索引列的长度过长,索引时将产生很大的索引文件,同时索引速度降低。
前缀索引通过限制字符列索引的长度,减少索引文件大小,加快索引查询长度。
最左前缀原理
MySQL查询按照索引定义从左到右的方式使用索引。
假设有组合索引:<emp_no,title,from_date>
- 全列匹配
当按照索引中所有列进行精确匹配(这里精确匹配指“=”或“IN”匹配)时,索引可以被用到。这里有一点需要注意,理论上索引对顺序是敏感的,但是==MySQL的查询优化器会自动调整where子句的条件顺序以使用适合的索引。==
- 最左前缀匹配
当查询条件精确匹配索引的左边连续一个或几个列时,如<emp_no>或<emp_no,title>,索引可以被用到,但是只能用到一部分,即条件所组成的最左前缀。
- 查询条件用到了索引中列的精确匹配,但是中间某个条件未提供。
SELECT * FROM employees.titles WHERE emp_no='10001' AND from_date='1986-06-26';
查询只用到了索引的第一列,而后面的from_date虽然也在索引中,但是由于title不存在而无法和左前缀连接,因此需要对结果进行扫描过滤from_date。
在Title列数据较少时,可以使用填坑法让mySql使用索引查询:
SELECT * FROM employees.titles
WHERE emp_no='10001'
AND title IN ('Senior Engineer', 'Staff', 'Engineer', 'Senior Staff', 'Assistant Engineer', 'Technique Leader', 'Manager')
AND from_date='1986-06-26';
- LIKE和REGEXP
LIKE匹配时,只有%不出现在开头,才会用到索引。
REGEXP匹配,不会用到索引。
- 范围查询
范围列可以用到索引(必须是最左前缀),但是范围列后面的列无法用到索引。
索引最多用于一个范围列,因此如果查询条件中有两个范围列则无法全用到索引。
有时,==MySQL会将BETWEEN优化为IN,从而使用索引匹配。==
- 查询条件含有函数或表达式
如果查询条件含有函数或表达式,MySQL不使用索引。
- 字符串与数字比较时不走索引
-- 字符串与数字比较不使用索引; CREATE TABLE `a` (`a` char(10)); EXPLAIN SELECT * FROM `a` WHERE `a`="1" -- 走索引 EXPLAIN SELECT * FROM `a` WHERE `a`=1 -- 不走索引 - ==如果条件中有or,除非所有or字段都有索引,否则不走索引。==
select * from dept where dname='xxx' or loc='xx' or deptno=45 --如果条件中有or,即使其中有条件带索引也不会使用。换言之,就是要求使用的所有字段,都必须建立索引,我们建议大家尽量避免使用or 关键字 - ==如果MySQL估计使用全表扫描比使用索引快,不走索引。==
-- 如果mysql估计使用全表扫描要比使用索引快,则不使用索引
索引选择性和索引前缀优化
索引选择性(Selectivity)
两种情况不建议为列添加索引:
- 表记录较少,通常表记录2000条以上才考虑需要添加索引。
- 索引选择性(Selectivity)较低。
索引选择性(Selectivity)是指不重复的索引值(Cardinality,基数)与表记录数的比值:
Selectivity(Title) = count(DISTINCT(title))/count(*);
前缀索引优化
基于索引选择性,可以对索引做前缀索引优化,根据索引选择性的值,选择合适的前缀建立索引,而不是对列的全值建立索引,大大减少索引大小,提高索引查询速度。
例子:对<first_name, last_name>,计算不同的前缀索引选择性大小:
SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.9313 |
+-------------+
SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.7879 |
+-------------+
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.9007 |
+-------------+
可知,相对于直接使用<first_name, last_name>,对<first_name, left(last_name,4)>建立索引:
- 选择性减少不多,几乎相同。
- 索引长度大大减少。
因此,可以对
<first_name, left(last_name,4)>建立索引,替代<first_name, last_name>:ALTER TABLE employees.employees ADD INDEX `first_name_last_name4` (first_name, last_name(4));
索引主键选择
在使用InnoDB存储引擎时,由于InnoDB使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。因此,==使用与业务无关的自增主键(id primary key auto_increment)作为索引要好于使用数据中的唯一字段。==
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。
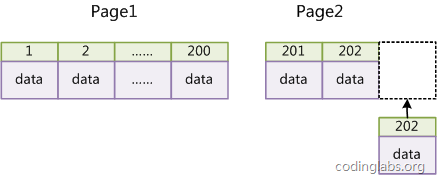
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置:
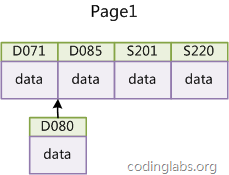
此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
因此,只要可以,请尽量在InnoDB上采用自增字段做主键。
REFS
- https://blog.codinglabs.org/articles/theory-of-mysql-index.html
- http://www.runoob.com/w3cnote/mysql-index.html
- https://tech.meituan.com/2014/06/30/mysql-index.html
- https://dev.mysql.com/doc/refman/5.7/en/innodb-restrictions.html
- https://www.xuebuyuan.com/3241057.html
- https://segmentfault.com/a/1190000008131735
本文地址:https://cheng-dp.github.io/2019/05/20/mysql-index/